
Yihao (Q) Quan
Incoming Ph.D. Student @ Rutgers University
News
EMNLP 2025 Oral

One co-first author paper got accepted and selected by EMNLP 2025 Oral
ACL 2025 @ KnowFM
One co-first paper got accepted by ACL 2025 @ KnowFM
NAACL 2025 Oral
One co-first author paper got accepted selected as NAACL 2025 Oral
AAAI 2025
One paper got accepted by AAAI 2025

Yihao (Q) Quan, currently an incoming Ph.D. Student at Rutgers University under the esteemed guidance of Prof. Ruixiang (Ryan) Tang. I obtained my B.S. degree at Beijing Jiaotong University in July 2025.
Research Interests
My research primarily focuses on MultiModal Learning and Trustworthy & Interpretability AI, with a emphasis on the following areas:
- Vision + Language: Bridging the gap between language and vision representation, providing a foundation for more interpretable and controllable multimodal systems.
- Unify Multimodal Understanding and Generation: Bridging architectural differences between autoregressive and diffusion models via mutual promotion of understanding and generation.
- Mechanistic Interpretability: Understanding the internal mechanisms of LLMs and MLLMs.
- Hallucination, Factuality and Safety: Using the interpretability findings to help downstream tasks and design safer models.
Selected Publications
* = Equal Contribution
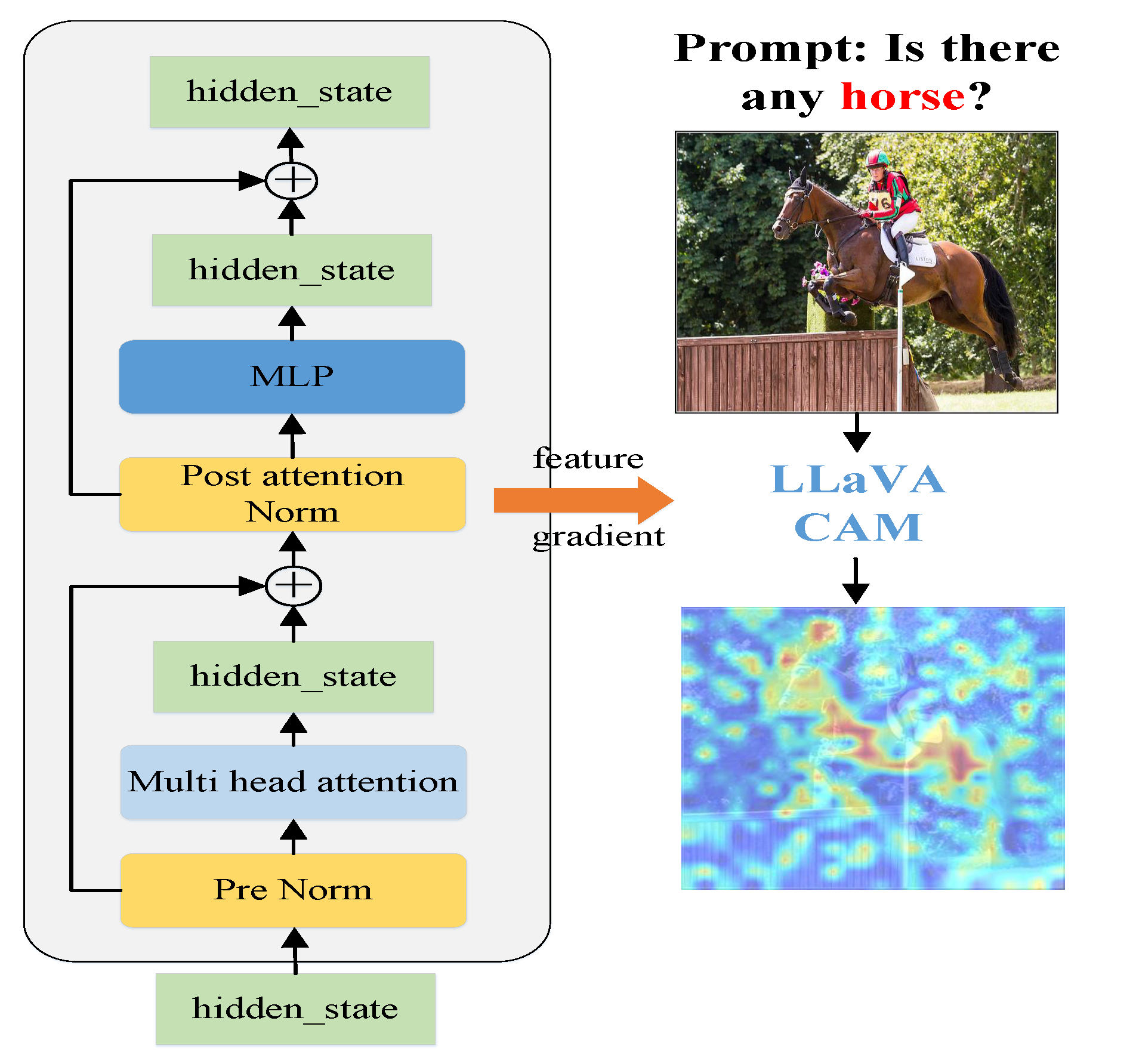



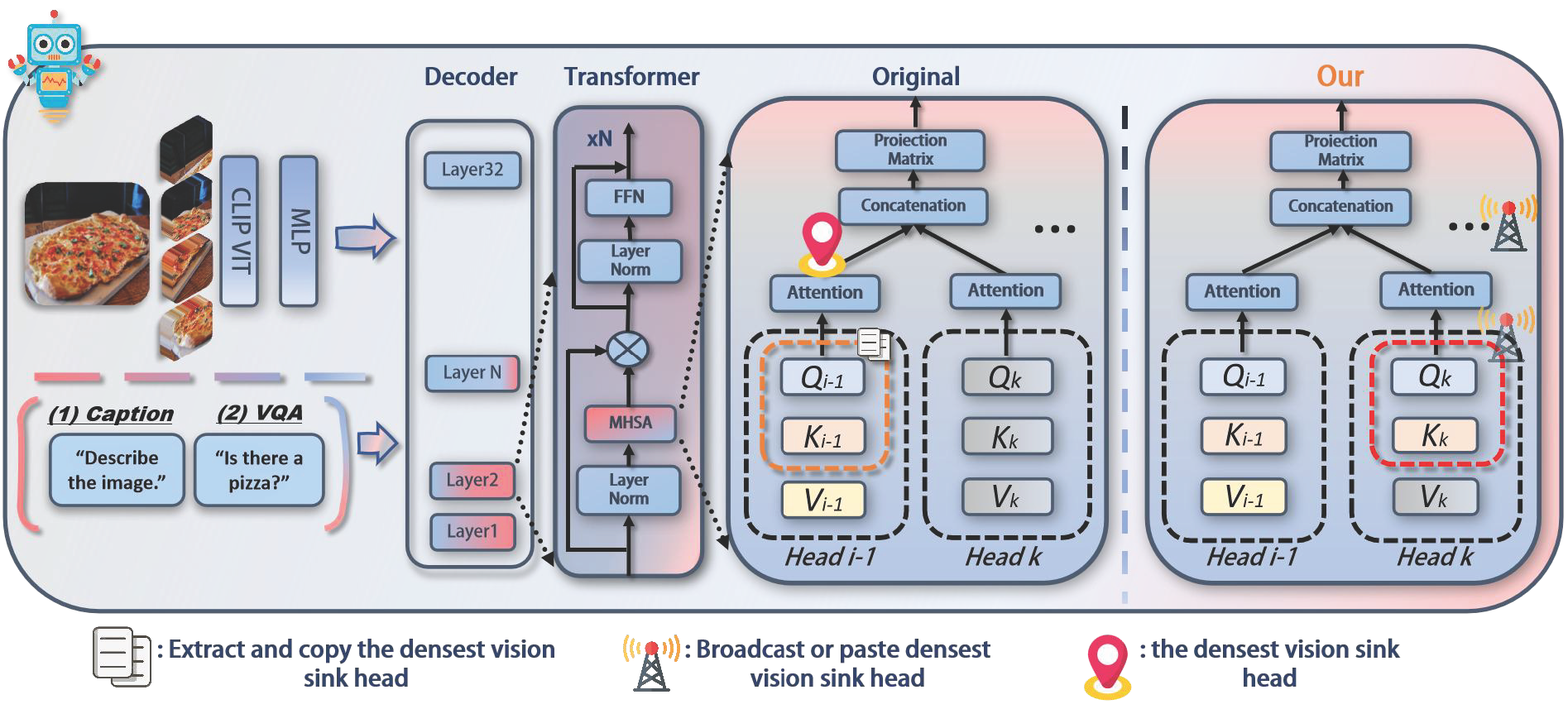

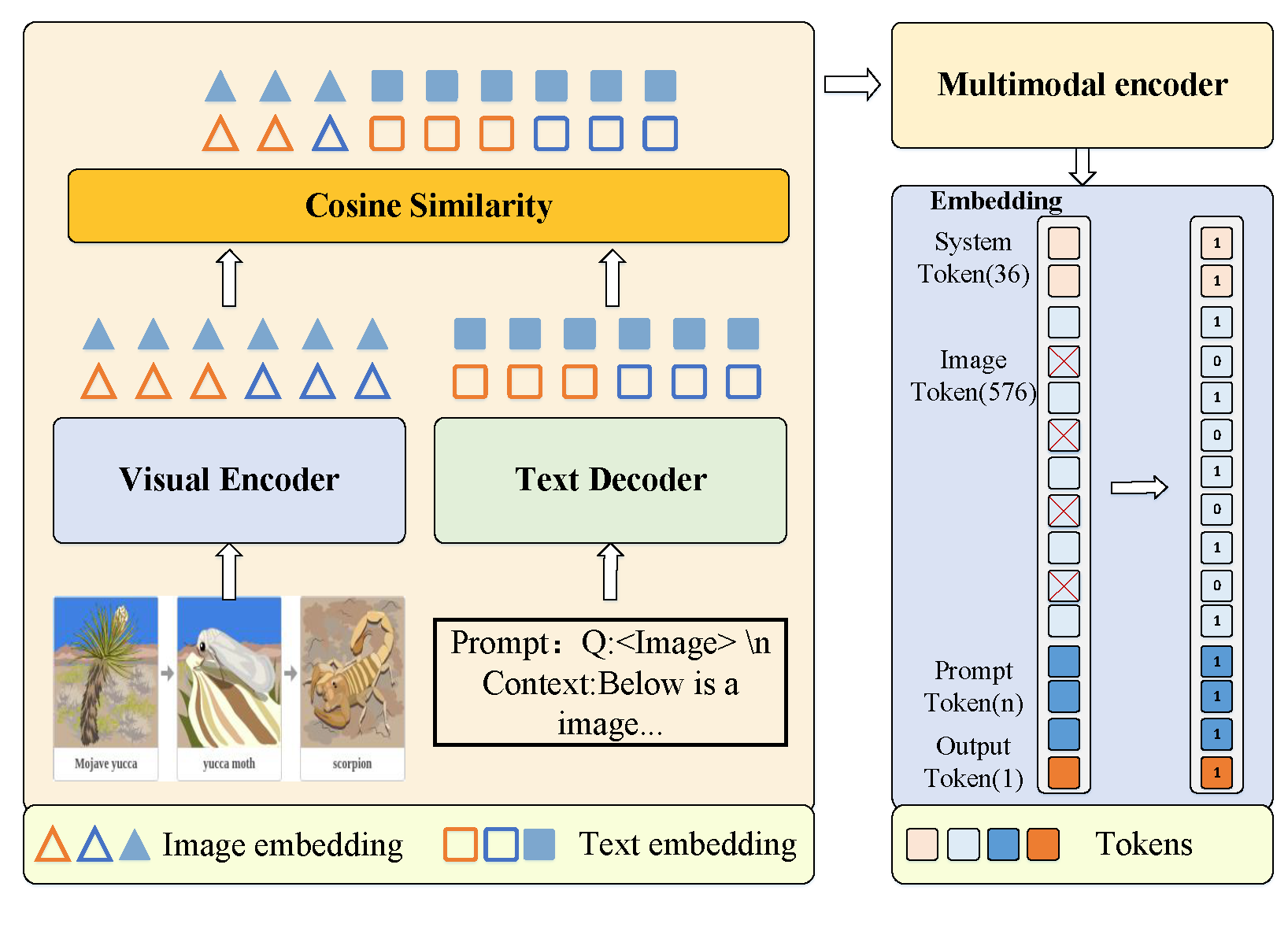

Photo Gallery
All
2025
2024









Selected Awards and Honors
- 2021-2025: Dean's List of Rochester Institute of Technology
- 2021-2025: Merit Student of Beijing Jiaotong University
- 2022: Second Prize of National College Student Mathematical Modeling Competition
- 2022: Kaggle Sliver Medal (Top 5%): Feedback Prize - Evaluating Student Writing